克雷西 发自 凹非寺

推箱子、俄罗斯方块……这些人类的经典怀旧小游戏,也成大模型bench**rk了。
o3-pro刚刚也挑战了这两款游戏,而且表现还都不错,直接突破了bench**rk上限。
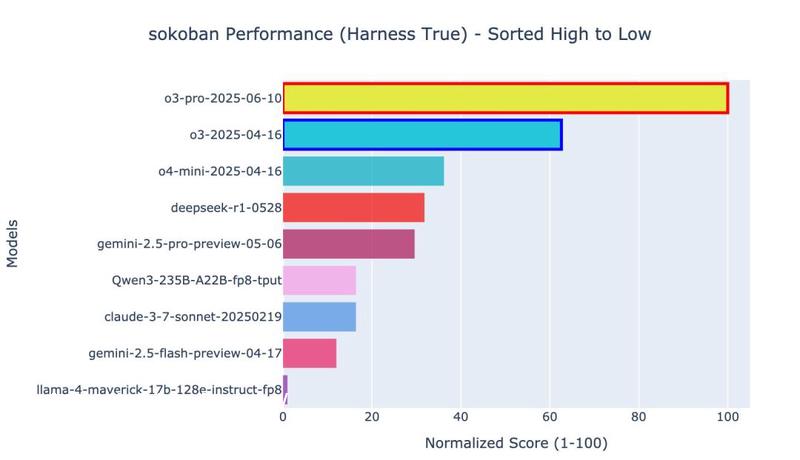
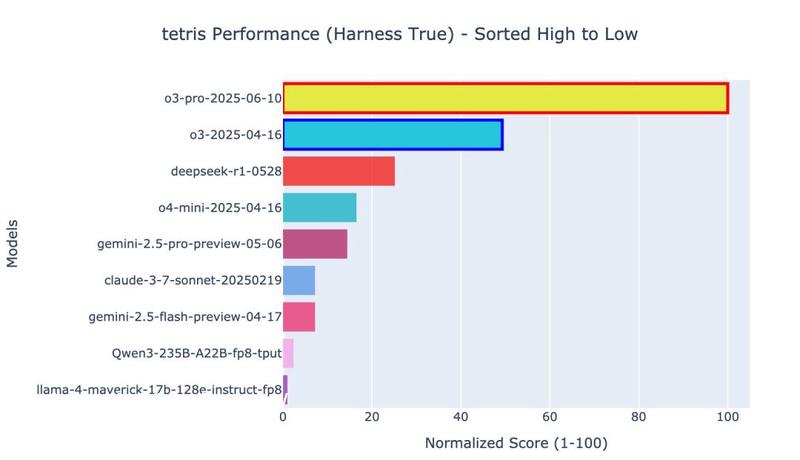
具体来说,bench**rk中推箱子一共就只做到了被o3-pro突破的第六关;俄罗斯方块则是强行终止的结果,实际上o3-pro根本停不下来。
如果和前SOTA——o3比较,o3-pro的成绩也是直接翻倍。
还有网友直言,比起大模型竞技场,这套标准才更适合做测试大模型的基准。

o3-pro挑战的这两个游戏,出自一套名为Lmgame的bench**rk,顾名思义就是让大模型玩游戏。
o3-pro挑战的推箱子是从19***的版本修改而来,在o3-pro之前,评估指标是游戏结束之前推动到目标位置的箱子总数。
不过这次o3-pro直接把所有关卡都通了,颇有种“得一百分是因为卷面只有一百分”的感觉。
但也不必担心,测试基准会动态更新,GItHub仓库中半个月前更新的游戏地图还只有四关,原版游戏更是有足足50多个关卡。
而在o3-pro挑战之前,表现**的是o3,o4-mini紧随其后,再然后是DeepSeek-R1的最新版本(0528)。
俄罗斯方块的得分计算方式则是将放置的方块数量与清除行数的10倍相加,直到游戏结束。
在o3-pro之前,表现**的模型同样是o3,但后面R1和o4-mini的排名和推箱子相比**了位置。
不过在时间上,o3-pro的操作相当耗时,每走一步都要花上好几分钟。
另外还有网友认为,如果让大模型编写程序而不是直接挑战,结果可能会更好。
除了o3-pro玩的推箱子和俄罗斯方块,Lmgame中还包括四款游戏——2048、糖果传奇、马里奥兄弟和逆转裁判。
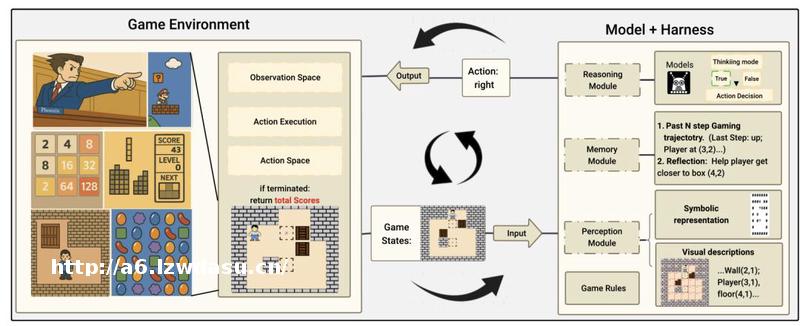
测试过程中通过一种迭代交互循环模式进行,游戏环境会持续地向大模型提供游戏状态,这些动作随后在游戏环境中被执行,接着游戏状态会更新以进行下一轮决策。
同时还引入了智能体框架作为辅助工具,其中包含了感知、记忆、推理等模块;为了确保评估结果的稳定*和可比*,该模式还实施了提示标准化,以减少提示提示词带来的*能波动。
具体到每个游戏的评价方式也有所区别:
**马里奥兄弟:衡量标准是马里奥在所有关卡中累积的水平移动距离(以游戏单位计算),
2048:评估指标是所有合并方块值的总和,记录直到棋盘停滞(连续十回合没有合并或棋盘变化)为止,取以2为底的对数后乘10即为最终分数。
糖果传奇:评价标准是在固定的 50 回合内消除的糖果总数。
直到犯下五次错误决策(即生命值用尽)为止。
不过这些游戏表现的衡量标准当中,都没有将时间作为考量因素。
团队表示马上安排。
说到宝可梦,Gemini一直在全网**当中进行挑战,并且在今年5月初成功通关了宝可梦·蓝。
当时谷歌CEO劈柴哥**时间**官宣,还放出了通关时刻的珍贵影像:
这个项目来自UCSD的Hao AI Lab,附属于USCD的机器学习系统实验室和NLP实验室,
张昊本硕*分别就读于华南理工、上海交大和卡内基梅隆大学,之后到UC伯克利从事*士后研究,结束后加入UCSD。
此外张昊也参与过创立LMSYS,并担任大模型竞技场顾问。
LMSYS是一个非营利组织,大模型竞技场和**模型框架SGLang、vLLM都是由LMSYS**的。
说回Hao AI Lab,该实验室创立了多个开源项目,其中GitHub星标数最多的是视频生成加速框架FastVideo,已获得1.5k星。
Hao AI Lab还接受谷歌和英伟达的资助,今年5月英伟达给该实验室捐赠了一台DGX B200。
项目仓库:
榜单:
论文:
人类怀旧小游戏成了大模型新Bench**rk》




发表评论